Rozptyl podruhé
V popisu výběrového rozptylu chybí důkaz nebo jakékoli vysvětlení, proč je zavedení výběrového rozptylu vlastně potřeba a proč vzorec na rozptyl nelze použít pro nestranný odhad. Tomu se budeme věnovat nyní.
Nejprve si odvodíme takzvaný výpočetní tvar pro rozptyl. Víme, že populační rozptyl se spočte pomocí vztahu
Pro výpočet hodnoty rozptylu pomocí kalkulačky je tento vzorec poměrně nepraktický, protože pro každou hodnotu souboru je potřeba zadat rozdíl mezi danou hodnotou a střední hodnotou. Můžeme ale provést následující úpravy:
Výsledný výpočetní tvar pro rozptyl má tvar
Stačí tedy vypočítat součet druhých mocnin hodnot souboru a odečíst od něj druhou mocninu součtu hodnot, což rychlost výpočtu podstatně sníží. Tento vztah ještě využijeme níže.
Nyní se ale vraťme k výběrovému rozptylu. Jestliže máme k dispozici pouze náhodný výběr z nějakého souboru (a nikoli všechny hodnoty souboru), zpravidla nebudeme znát střední hodnotu základního souboru. Tuto střední hodnotu musíme odhadnout pomocí aritmetického průměru. Dokažme si nejprve, že aritmetický průměr je nezkresleným odhadem střední hodnoty, tj. určíme si střední hodnotu aritmetického průměru:
Využíváme dvou známých vlastností střední hodnoty. Při násobení náhodné veličiny konstantou 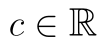 platí, že
platí, že
A dále střední hodnota součtu náhodných veličin se rovná součtu středních hodnot náhodných veličin:
Střední hodnota aritmetického průměru je tedy skutečně střední hodnotou náhodného výběru, tím pádem je dokázáno, že takový odhad je nezkreslený. Vraťme se nyní ke vzorci pro populační rozptyl:
Namísto střední hodnoty nyní do vzorce dosadíme aritmetický průměr. Takto upravenou statistiku si označíme jako 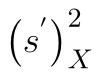 :
:
Nyní použijeme známý vzorec 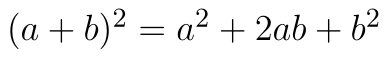 a provedeme několik jednoduchých úprav.
a provedeme několik jednoduchých úprav.
V případě druhého sčítance na posledním řádku provádíme součet vzájemných násobků hodnot v náhodném výběru. Výraz lze zapsat též jako
protože rozlišujeme mezi případy, kdy jsou mezi sebou násobeny dva různé náhodné výběry, a kdy je násobena tatáž realizace náhodného výběru. Tím jsme získali upravený vzorec pro statistiku :
Abychom si ukázali, jak je statistika zkresleným odhadem rozptylu, určíme si její střední hodnotu:
Uvažujeme, že jednotlivé realizace náhodného výběru jsou vzájemně nezávislé, tj. hodnoty 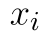 a
a 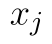 jsou pro
jsou pro 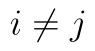 nezávislé. V tom případě pak platí vztah
nezávislé. V tom případě pak platí vztah
Protože se ale v obou případech jedná o náhodný výběr ze stejného souboru se střední hodnotou 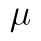 , platí dokonce
, platí dokonce
Dále máme v rovnici výraz 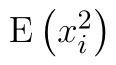 . Upravíme-li si rovnici pro výpočetní tvar rozptylu, kterou jsme odvodili výše, zjistíme, že
. Upravíme-li si rovnici pro výpočetní tvar rozptylu, kterou jsme odvodili výše, zjistíme, že
Dosaďme tedy za oba výrazy a pokračuje v odvození
Vidíme tedy, že střední hodnota statistiky je
Abychom tedy získali nezkreslený odhad rozptylu, museli bychom statistiku násobit výrazem 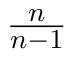 . Na základě této myšlenky je pak odvozen vzorec pro výběrový rozptyl. Výraz je někdy nazýván jako Besselova korekce. Výraz konverguje k 1, pro velmi velké náhodné výběry je rozdíl mezi statistikami zanedbatelný. Protože střední hodnota statistiky konverguje k hodnotě rozptylu, je asymptoticky nestranným odhadem rozptylu.
. Na základě této myšlenky je pak odvozen vzorec pro výběrový rozptyl. Výraz je někdy nazýván jako Besselova korekce. Výraz konverguje k 1, pro velmi velké náhodné výběry je rozdíl mezi statistikami zanedbatelný. Protože střední hodnota statistiky konverguje k hodnotě rozptylu, je asymptoticky nestranným odhadem rozptylu.