Pravděpodobnostní rozdělení
V této lekci projdeme následující témata:
- pravděpodobnostní rozdělení náhodných veličin,
- testování hypotéz,
- modul
scipy.
Máme-li k dispozici nějaká data, nezajímají nás pouze statistické ukazatele jako průměr nebo rozptyl, ale i takzvané pravděpodobnostní rozdělení. Pravděpodobnostní rozdělení nám umožňuje popsat data pomocí matematické funkce.
Pravděpodobnostních rozdělení existuje mnoho, například na Wikipedii je jich popsáno několik desítek. My se podíváme pouze na několik z nich.
Normální rozdělení
Asi nejznámější statistické rozdělení dat je normální rozdělení, které je reprezentováno Gaussovou křivkou. Na něm si ukážeme, co vlastně pravděpodobnostní rozdělení je.
Zkusme využít modul scipy, který slouží k vědeckým výpočtům.
Vygenerujme si soubor dat, která mají normální rozdělení. Z náhodně generovaných dat si vytvoříme histogram.
import numpy
from scipy.stats import norm
import matplotlib.pyplot as plt
mu = 100
sigma = 15
data = norm.rvs(loc=mu, scale=sigma, size=100_000)
plt.hist(data, 30, density=True)
U histogramu můžeme měnit parametr bins, která říká, na kolik intervalů je histogram rozdělen. Histogram nám říká,
kolik hodnot se nachází v jednotlivých číselných intervalech.
Nyní náš čeká poněkud abstraktní úvaha. Uvažujme, že máme neomezené množství dat a tím pádem můžeme neomezeně zvětšovat počet intervalů, ze kterých je složen histogram. Současně zmenšujeme šířku každého z intervalů. Tím, jak zvyšujeme počet intervalů, se nám graf "vyhlazuje" a postupně se začíná přibližovat červené čáře.
Červená čára je označována jako funkce hustoty a funguje podobně jako histogram. Pokud si vybereme dvě hodnoty, plocha pod funkcí hustoty nám řekne, kolik procent všech hodnot v nějakém souboru se nachází v daném intervalu.
fig, axs = plt.subplots(2, 2)
for i in range(0, 4):
count, bins, ignored = axs[i // 2, i % 2].hist(data, (i + 1) * 10, density=True)
axs[i // 2, i % 2].plot(bins, norm.pdf(bins, mu, sigma), linewidth=1, color='r')
Funkce hustoty je matematická funkce, která udává "tvar" rozdělení. Zpravidla má ale jeden nebo více parametrů, kterým modelujeme rozdělení konkrétních dat. Normální rozdělení má například inteligence nebo výška populace. Je ale zřejmé, že obě veličiny musejí mít různá rozdělení, protože průměrná výška mužů je asi 181 cm a průměrné IQ 100. Funkce hustoty normálního rozdělení má jako parametry střední hodnotu a rozptyl (nebo směrodatnou odchylku), pro inteligenci a výšku tedy vložíme konkrétní parametry a získáme dvě funkce, které věrně modelují rozložení daných dat.
Tyto parametry jsme vkládali do funkce rvs jako loc (od location) a scale. Jako loc jsme vložili průměrnou
hodnotu 100 a jako scale směrodatnou odchylku 15.
Normální rozdělení je symetrické a hodnoty kolem průměru se vyskytují mnohem častěji. Protože mají data normální rozdělení, většina populace se pohybuje v blízkosti průměru (např. v intervalu 80 až 120) a odlehlých hodnot (např. geniálních lidí) je v populaci velmi málo. Pokud by například měla inteligence rovnoměrné rozdělení, tak by průměrně inteligentních lidí bylo stejně jako geniálních.
Rozdělení nám řekne mnohem více než statistické ukazatele. Pokud bychom například vyráběli oblečení, můžeme si pomocí něj spočítat, kolik oblečení v různých velikostech bychom měli vyrábět, aby odpovídalo potenciální poptávce zákazníků.
Pro takové výpočty je často vhodná i distribuční funkce, která nám odpovídá na otázku, kolik procent hodnot z daného souboru jsou menší než nějaké číslo. Distribuční funkci si můžeme představit jako kumulativní součet funkce hustoty.
Uvažujme například, že chceme vědět, jaké procento populace má výšku mezi 178 a 186 cm, abychom věděli, jaké procento našich kalhot má být vyrobeno ve velikosti L.
Nejprve zjistíme, jaké procento mužů má výšku do 178 cm.
from scipy.stats import norm
print(norm.cdf(178, 180, 8))
Nyní spočítáme, jaké procento mužů má výšku do 186 cm.
print(norm.cdf(186, 180, 8))
Nyní zbývá spočítat rozdíl těchto hodnot.
print(norm.cdf(190, 180, 8) - norm.cdf(185, 180, 8))
Výsledek je přibližně 0.16, tedy triček velikosti L bychom měli vyrábět přibližně 16 %.
Další rozdělení
Existuje mnoho dalších rozdělení.
Exponenciální rozdělení
Níže je například exponenciální rozdělení, které se oproti normálnímu jasně liší tím, že není symetrické.
Exponenciální rozdělení často popisuje interval mezi dvěma náhodnými událostmi, například mezi příchody dvou zákazníků do obchodu, mezi dvěma zemětřeseními, přichozími hovory do call centra atd.
Exponenciální rozdělení má jen jeden parametr a tím je průměrný počet událostí za časovou jednotku.
Uvažujme třeba, že průměrný interval mezi dvěma příchozími hovory do call centra jsou 2 minuty.
from scipy.stats import expon
scale = 2
data = expon.rvs(scale=scale, size=100_000)
count, bins, ignored = plt.hist(data, 40, density=True)
plt.plot(bins, expon.pdf(bins, scale=scale), linewidth=1, color='r')
Celočíselná rozdělení
Existují i statistická rozdělení, která modelují celočíselné statistické veličiny. Například uvažujme, že hodíme
desetkrát mincí a zajímá nás, kolikrát může padnout líc. To můžeme zjistit pomocí binomického rozdělení. Pomocí
něj modelujeme situaci, že provedeme 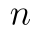 pokusů a úspěch v pokusu (v našem případě padnutí líce) je roven
pokusů a úspěch v pokusu (v našem případě padnutí líce) je roven 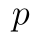 .
.
from scipy.stats import binom
n = 10
p = 0.5
data = binom.rvs(n=n, p=p, size=100_000)
plt.hist(data, bins=range(0, n+2), density=True)
Pro celočíselná (diskrétní) rozdělení nekreslíme funkci hustoty, ale používáme tzv. pravděpodobnostní funkci,
která je nespojitá. Parametrem této funkce u binomického rozdělení je pravděpodobnost úspěchu jednoho pokusu a
značíme ho jako .
Pro binomické rozdělení platí, že je symetrické pro 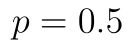 a nesymetrické pro ostatní hodnoty.
a nesymetrické pro ostatní hodnoty.
Například uvažujme písemnou zkoušku, která má 20 otázek a každá otázka má 4 možné odpovědi, z nichž je právě 1 správná. Pomocí binomického rozdělení můžeme snadno spočítat, jaká je pravděpodobnost, že v testu uspějeme tipováním.
import pandas
n = 20
p = 0.25
points = list(range(0, 21))
data = binom.cdf(points, n, p)
data = pandas.DataFrame(data)
data["Color"] = numpy.where(data.index > 10, "green", "red")
data[0].plot(kind="bar", color=data["Color"])
Červené sloupce znamenají, že jsme v testu neuspěli. Bohužel je pravděpodobnost neúspěchu téměř 100 %.